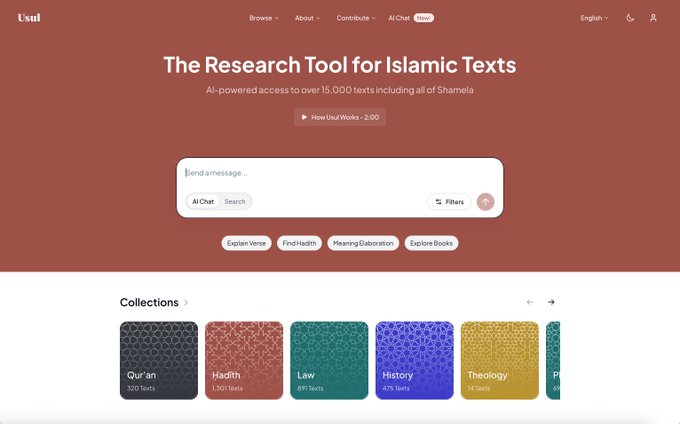
Over the past year, I've worked on Usul - an AI search engine on top of 15,000 classical Islamic texts. It was one of the most difficult but also rewarding projects that I've worked on.
Usul was challenging for two reasons:
- Scale: 6 billion tokens worth of content
- Accuracy: very little tolerance for mistakes
The Rabbit Hole
In order to incorporate AI with such massive datasets, developers use a technique called RAG (Retrieval-Augmented Generation). The core idea is simple: instead of overwhelming an LLM with millions of pages, you build a retrieval layer that acts like a smart filter. It finds the most relevant 10-20 pages for each query, then passes just those to the AI.
We kicked off the work and went down a rabbit hole of research: langchain, llamaindex, chunking, qdrant, milvus,… trying to make sense of how this would work, until we settled on a setup with llamaindex and qdrant. We were quite psyched, except that our setup didn't work. Chunks would get dropped, Qdrant would go down with traffic, and even when everything was in place, the quality of answers was subpar.
We spent the following months learning best practices and optimizing every piece, until we created the first end-to-end internal build. I tried it out, and my first reaction was "Oh my god, this is amazing masha'Allah".
The team rallied behind this reaction, and we put all resources behind the initiative. We started a beta period with 200 users—feedback was overwhelmingly positive. We did a public launch, hit 30K monthly active users, and saw the strongest retention metrics since starting Usul.
From Good to Excellent
The optics were positive from the outside, but internally, we saw many ways for the AI to improve: hybrid search, agentic retrieval, evaluation loops, deep research, and more. These were what we needed to deliver truly state-of-the-art accuracy, but they weren't feasible to build as a 2-person engineering team also trying to ship product features and support users.
As we talked to other AI companies building domain-specific products, we realized this problem wasn't unique to Usul. Every company wants state-of-the-art retrieval. Nobody wants to spend months figuring it out.
So.. we're starting a new company. Agentset.
Agentset is retrieval-as-a-service: upload your data, get SoTA retrieval out of the box.
We've already seen it outperform hand-built pipelines across two domains.
We'll be working on Agentset full-time while remaining available to support Usul. If you're working on an AI product and wrestling with retrieval, I'd love to talk.